Kijk mee met ons R&D team: een blik op woordsuggesties
Even voorstellen
Afgelopen jaar is Gerimedica een R&D team gestart. R&D staat voor Research en Development en is, letterlijk vertaald, ‘onderzoek en ontwikkeling’. Dit is dan ook precies wat ons R&D team doet. Het team heeft als doel te onderzoeken welke innovatieve technologieën in de (nabije) toekomst een plek zouden kunnen krijgen in Ysis. Vervolgens ontwikkelt het team ook prototypes van deze mogelijke features.
Via blogs geven we regelmatig een update over de ontwikkelingen waar het team zich mee bezig houdt. In deze eerste update willen we graag vertellen over één zo’n nieuw feature waar we achter de schermen aan werken, namelijk slimme woordsuggesties.
Wat zijn woordsuggesties?
Woordsuggesties, ook wel autocompletion of predictive text genoemd, is een functie die je waarschijnlijk vaak tegenkomt en misschien (al dan niet onbewust) gebruikt in het dagelijks leven. Deze functie biedt jou ondersteuning bij tekstinvoer, door een voorspelling te doen welk woord of welke woorden je wil intoetsen. Een correct voorspeld woord kun je vervolgens met één druk op de knop overnemen.
Vooral op apparaten zonder fysiek toetsenbord, zoals mobiele telefoons of tablets, kan dit het invoeren van tekst makkelijker en sneller maken. De laatste jaren duikt de functionaliteit ook op in bijvoorbeeld mailprogramma’s of tekstverwerkers zoals Microsoft Word. Figuur 1 toont enkele voorbeelden: Google’s zoekbalk die suggesties geeft als je een zoekopdracht begint te typen, text prediction op de iPhone en Gmail die suggesties biedt bij het schrijven van een mail.
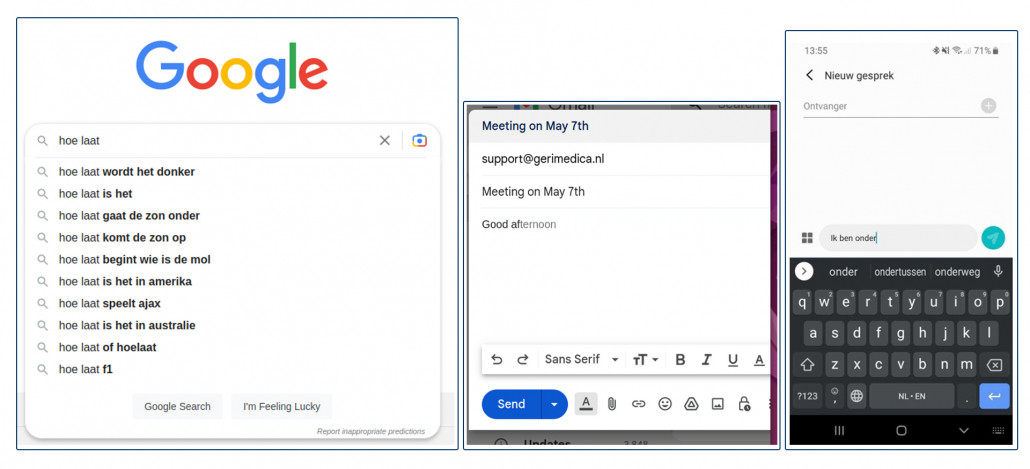
Figuur 1: een paar voorbeelden van woordsuggesties in andere applicaties.
Voordelen van woordsuggesties voor verslaglegging in de zorg
Woordsuggesties kunnen overal waar je typt toegepast worden, dus ook in Ysis. Wat kunnen woordsuggesties toevoegen aan verslaglegging in de zorg? We hebben de belangrijkste voordelen voor je op een rij gezet:
- Tijdsbesparing. Door langere woorden met een druk op de knop in te voeren, in plaats van letter voor letter, gaat het intypen van een rapportage sneller.
- Spelling. De getoonde woorden zijn correct gespeld. Dit verkleint de kans op spelfouten in de rapportage, met name voor (medisch) jargon.
- Minder afkortingen. Met woordsuggesties typ je een langer woord net zo snel als een afgekorte versie van dat woord (zoals vpk als afkorting voor verpleegkundige). Minder afkortingen leiden tot beter leesbare rapportages.
- Eenheid van taal. Door suggesties te tonen die in lijn zijn met de Eenheid van Taal-richtlijnen, werken we mee aan betere uitwisseling van informatie in de zorg.
Deze voordelen kunnen de administratieve last van zorgprofessionals verlichten. Dit is precies wat we als Gerimedica zo belangrijk vinden, en in lijn met het motto van Ysis: ‘meer bezig met je vak’.
Goede voorspellingen bepalen het succes
De levensvatbaarheid van deze functionaliteit staat of valt uiteindelijk met de nauwkeurigheid van de voorspellingen. Als de gegeven suggesties voor het woord te vaak onjuist of onzinnig zijn, dan zal een gebruiker de suggesties eerder als storend dan als nuttig ervaren.
Het genereren van goede voorspellingen is de rol van het taalmodel, een AI-programma dat zelfstandig teksten kan aanvullen en opstellen. Een taalmodel wordt getraind op een grote hoeveelheid teksten. Dit is meestal in een bepaalde taal en soms ook over een bepaald thema. Zo leert het model hoe vaak een woord in een bepaalde context voorkomt, of kan het een score geven die aangeeft hoe waarschijnlijk een bepaalde serie woorden is. Met deze kennis kan het model dus voorspellen wat het volgende woord is dat iemand wil typen, vooral als iemand al een paar letters van dat woord heeft getypt.
Met de komst van krachtiger computers en steeds meer beschikbare digitale teksten via internet heeft de ontwikkeling van taalmodellen de laatste jaren een grote vlucht genomen. Een recent voorbeeld is ChatGPT, een generatief taalmodel dat dankzij training op enorme hoeveelheden trainingsdata in staat is zelf allerlei teksten te produceren.
Kiezen van het juiste taalmodel van cruciaal belang
De keuze voor een passend taalmodel is dus van vitaal belang voor woordsuggesties. Het model moet rekening kunnen houden met de tekst die de gebruiker al ingevoerd heeft, maar ook getraind zijn op het juiste type taal. Tenslotte moet het snel genoeg werken om woorden te voorspellen terwijl een gebruiker aan het typen is.
Voor een eerste prototype van de woordsuggestie-functie hebben we twee bestaande taalmodellen getest: RobBERT en MedRoBERTa. Beiden zijn net als ChatGPT gebaseerd op de Transformer-architectuur, waardoor ze verbanden kunnen herkennen in lange stukken tekst. Ook zijn ze vrijelijk beschikbaar en aan te passen. Het belangrijkste verschil zit in het trainingsmateriaal. RobBERT is getraind op algemene teksten van het web. MedRoBERTa is gevoed met geanonimiseerde medische dossiers uit het Amsterdam UMC en dus meer toegespitst op geneeskunde en gezondheidszorg.
Vergelijking van taalmodellen RobBERT en MedRoBERTa
Om de twee modellen te vergelijken op het gebied van woordsuggesties, hebben we een bescheiden verzameling medische casussen uit het Nederlands Tijdschrift voor Geneeskunde samengesteld. Vervolgens hebben we gemeten hoe vaak een model het volgende woord in de teksten goed voorspelt aan de hand van de voorgaande zin, als een gebruiker al 0, 1, 2 of 3 letters heeft getypt. Figuur 2 toont het resultaat. Uiteraard worden beide modellen steeds beter in het voorspellen van het juiste woord als er meer beginletters worden gegeven, maar we zien in alle gevallen een duidelijke voorsprong voor MedRoBERTa op deze (medische) teksten. Als de gebruiker drie letters heeft getypt, wordt bijna de helft van de gevallen een juiste woordsuggestie gegeven!
Als volgende stap willen wij het taalmodel verder aanscherpen op het taalgebruik van alle Ysis-gebruikers. Dus niet enkel de taal van medici, maar ook op de taal van andere behandelaren. Op dit moment onderzoeken wij hoe we hiervoor geanonimiseerde data uit Ysis kunnen gebruiken als trainingsmateriaal, natuurlijk op zo’n manier dat de privacy van cliënten en patiënten gewaarborgd blijft.
Figuur 2: vergelijking tussen MedRoBERTa en RobBERT op woordvoorspelling in medische teksten.
De gebruikerservaring is net zo belangrijk
Minstens zo belangrijk als het taalmodel is de gebruikerservaring. Want hoe zorgen we ervoor dat de getoonde woordsuggesties niet storend zijn, en het makkelijk is om een voorgesteld woord tijdens het typen direct over te nemen, dan wel te negeren?
Onderstaand filmpje toont het huidige prototype. Hierin hebben we geprobeerd een balans te vinden door suggesties alleen te tonen als het taalmodel erg zeker is over het volgende woord én als het voorgestelde woord een minimaal aantal karakters langer is dan het al ingevoerde deel van het woord.

In een volgend stadium willen we samen met gebruikers testen hoe de ervaring verder verbeterd kan worden.
Onze vervolgstappen
Met deze blog geven we een korte impressie van de huidige status van ons onderzoek en de ontwikkeling van de functionaliteit woordsuggesties.
We zijn zeer tevreden met deze eerste resultaten, maar voor zowel de kwaliteit van de voorspellingen als voor een optimale gebruikerservaring is er nog werk aan de winkel. Met hulp en feedback van onze gebruikers hopen we deze volgende stappen te zetten en zo de functionaliteit gereed te maken voor integratie in Ysis.
Ons R&D team werkt ook aan andere innovaties. In een volgende update zullen we hier meer over vertellen. Heb je naar aanleiding van deze blog vragen, suggesties of ideeën? Neem dan gerust contact met ons op, dat vinden we alleen maar leuk! Je kunt ons bereiken op info@gerimedica.nl.
R&D team Gerimedica
